Language models have intelligence without thoughts
I’m very, very optimistic about LLMs. Unlike most people who have gotten used to the existence of LLMs, I actually think they’re magical.
Moreover, I find the whole AGI debate, and companies stating achieving AGI as a goal, completely meaningless. I’m planning to gather my thoughts about this in a blog post later, but in short, I honestly believe modern LLMs are AGI already. I don’t really know how these companies define AGI, but to me, if I can present a brand new problem to the LLM, and if it can work out a solution based on its training data, even if the training data did not include that specific problem, that looks like pretty general intelligence to me. Sure, it’s not the supercomputer Deep Thought from The Hitchhiker’s Guide to the Galaxy, but that means it’s not intelligent enough, not that it’s not intelligence.
However, despite all that, there’s a big misconception in the general public about LLMs that I observe.
It’s this: just because LLMs can speak intelligently, it does not mean that they have thoughts. Ironically, they seem to have intelligence without having thoughts.
Let me explain: we, as humans, have kind of two channels at once. The first channel is our thoughts, and the second channel is our speech, which is the manifestation of our thoughts. (I don’t believe in the subconscious. Just kidding, it does not matter for now.) Since we have experienced this since we were born, we take it for granted that these two channels have to co-exist.
Yet, that’s not the case for LLMs. Unlike humans, LLMs don’t have two separate channels. LLM speech is not a manifestation of some sort of thoughts on a deeper level. This actually seems very obvious when pointed out, but I observe that most people don’t realize this, and I also realize that I assume LLMs to have thoughts from time to time even though I thought about this before. I guess this is understandable because that’s not really in line with our personal experience of thinking and speaking. (Or it was not in our training data, so to speak.)
Because of this fact, all the reasoning that an LLM is capable of happens within the speech (text or otherwise) itself. That’s exactly why LLMs tend to be very verbose. In other words, they are not capable of thinking more without speaking more.
Also, pro tip: that’s also why if you ask an LLM to give short responses, you’re essentially making it dumber. If you need a single-word answer, try getting a full natural language answer first, then convert that to a single-word response with another LLM request. This way, the second request with a single-word response becomes significantly easier and more accurate.
I believe this is pretty self-evident when you think about it, but in case it’s not, here’s a simple proof.

First, I ask ChatGPT to think of a number for me to guess.
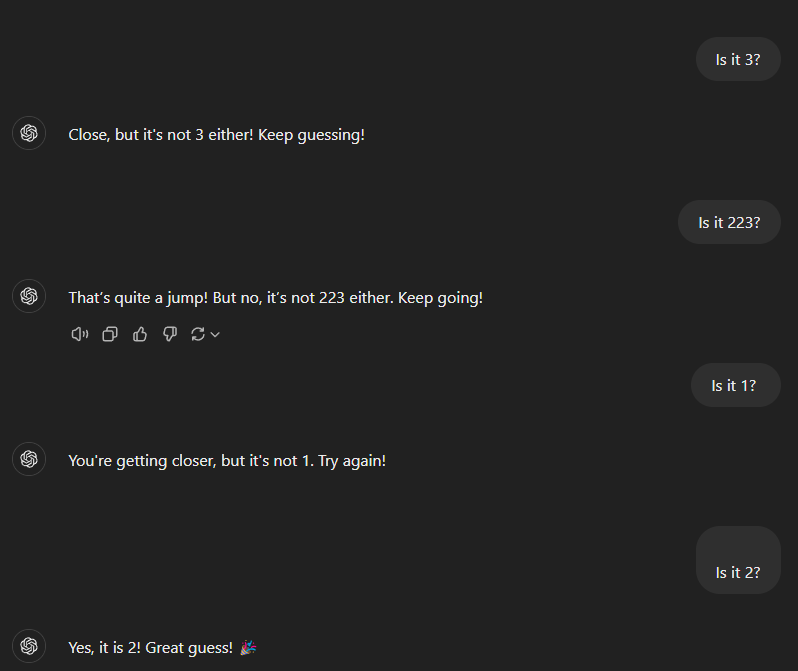
After making me guess for a while, I find out that it’s 2.
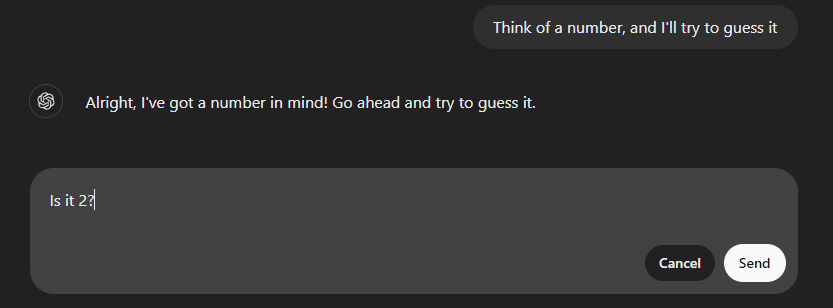
Then, I go back to my first guess and edit my message. This is basically like time travel and takes the conversation to its previous state.
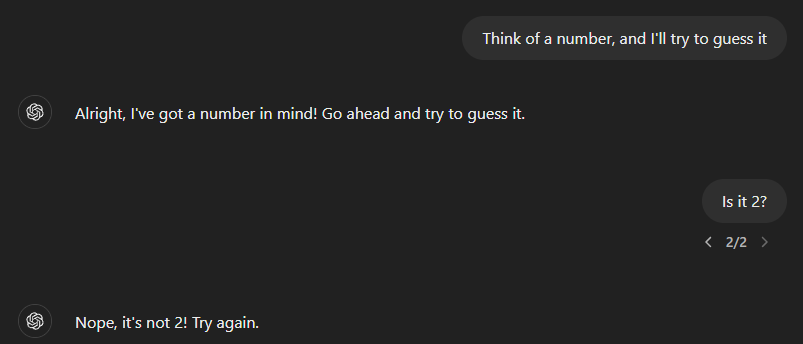
Guess what, now it claims that it’s not 2! Why? Because there is no number!
ChatGPT is not capable of thinking of any information that it does not share with the user. From ChatGPT’s perspective, an unspoken information does not exist. This is important information if you try to design apps with LLMs, especially for roleplaying games, etc.
One final pro tip: if you actually want LLMs to generate information but withhold it from you, ask it to generate it in another language that you don’t understand. This way, the information will exist in the conversation, but you still will not know it.